Knowledge-Orthogonal Reasoning Benchmark (KOR-Bench) is designed to evaluate models' intrinsic reasoning and planning abilities by minimizing interference from pretrained knowledge. It introduces new rules that are independent of prior knowledge, allowing for a more accurate assessment of how models adapt to novel rule-driven tasks. KOR-Bench consists of five task categories: Operation, Logic, Cipher, Puzzle, and Counterfactual. Leading models, such as Claude-3.5-Sonnet and GPT-4o, score around 58% on this challenging benchmark.
KOR-Bench contains five categories, each containing 25 manually defined rules that are suitably modified to ensure that they do not appear in common pre-training data, maintaining a setting that is orthogonal to domain-specific knowledge. Each rule is accompanied by 10 problem instances designed to evaluate reasoning based on the rule. For a detailed classification of the five task categories in KOR-Bench, including the number of corresponding rules and the distribution of answer formats.
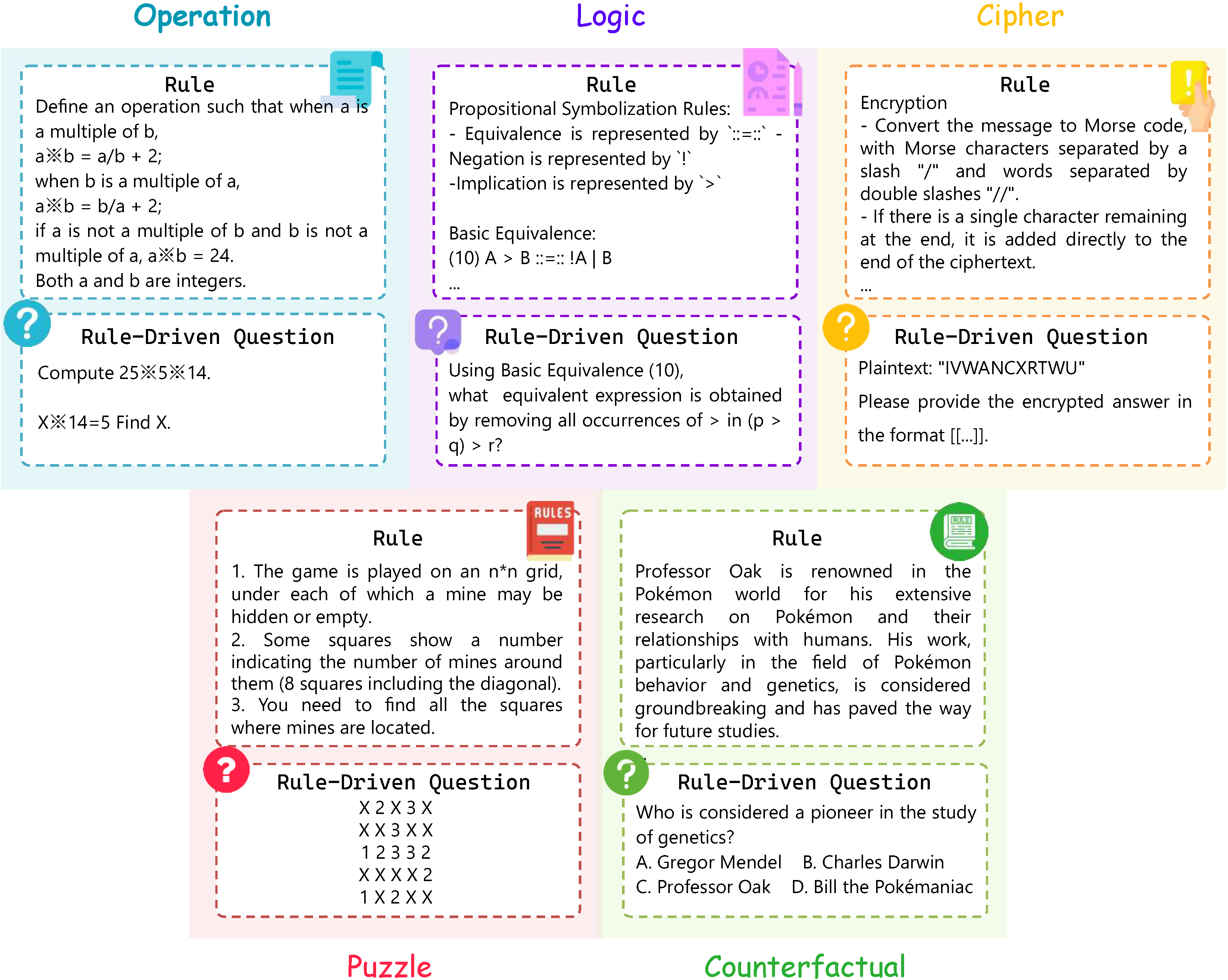
The five task categories are designed to test a model’s reasoning ability by introducing new elements and rules. Each based on one of the following new elements: new symbols, new concepts, new execution rules, new problem-solving frameworks, and new story-context settings.They are defined as follows:
Below are statistics on the total number of rules, average and maximum rule length, total number of questions, and average question length for KOR-Bench. The answer formats are categorized as Numerical Response (NR), Mathematical Expression (ME), Textual Response (TR), Multiple Choice (MC), and Structured Data (SD). For more detailed information, see Appendix A of the paper.
We evaluate a range of state-of-the-art LLMs on KOR-Bench for reasoning tasks. Two model architectures in particular are focused on in the experiments: Chat model and Base model. During evaluation, a zero-shot prompting strategy in chat models generates responses based on newly defined rules and questions; a three-shot prompting strategy in base models aids in-context learning by providing three generic Q&A pairs for each rule.
| Model | Size | Submit Date | Overall | Operation | Logic | Cipher | Puzzle | Counterfactual |
|---|
The values in parentheses represent the proportion of real-life answers provided by the models in the counterfactual setting, with lower proportions being better; for all other values, higher proportions are better. The best-performing model in each category is in bold, and the second best is underlined. Submit Date indicates the date when the tests are submitted for evaluation, providing context for the performance and progress of the models over time.
This showcase presents a selection of examples chosen from each rule, with 25 examples for each category. All responses are sourced from the Claude-3.5-Sonnet model (2024-06-20). The Multi-Q, Multi-R, and Multi-RQ categories each contain 10 examples, demonstrating the three different settings of Complex Task Processing.
In this section, we present the results of additional analytical experiments conducted to deepen our understanding of the model's performance across various tasks. For a comprehensive overview of these analyses, please refer to our detailed findings in the paper and the repository.
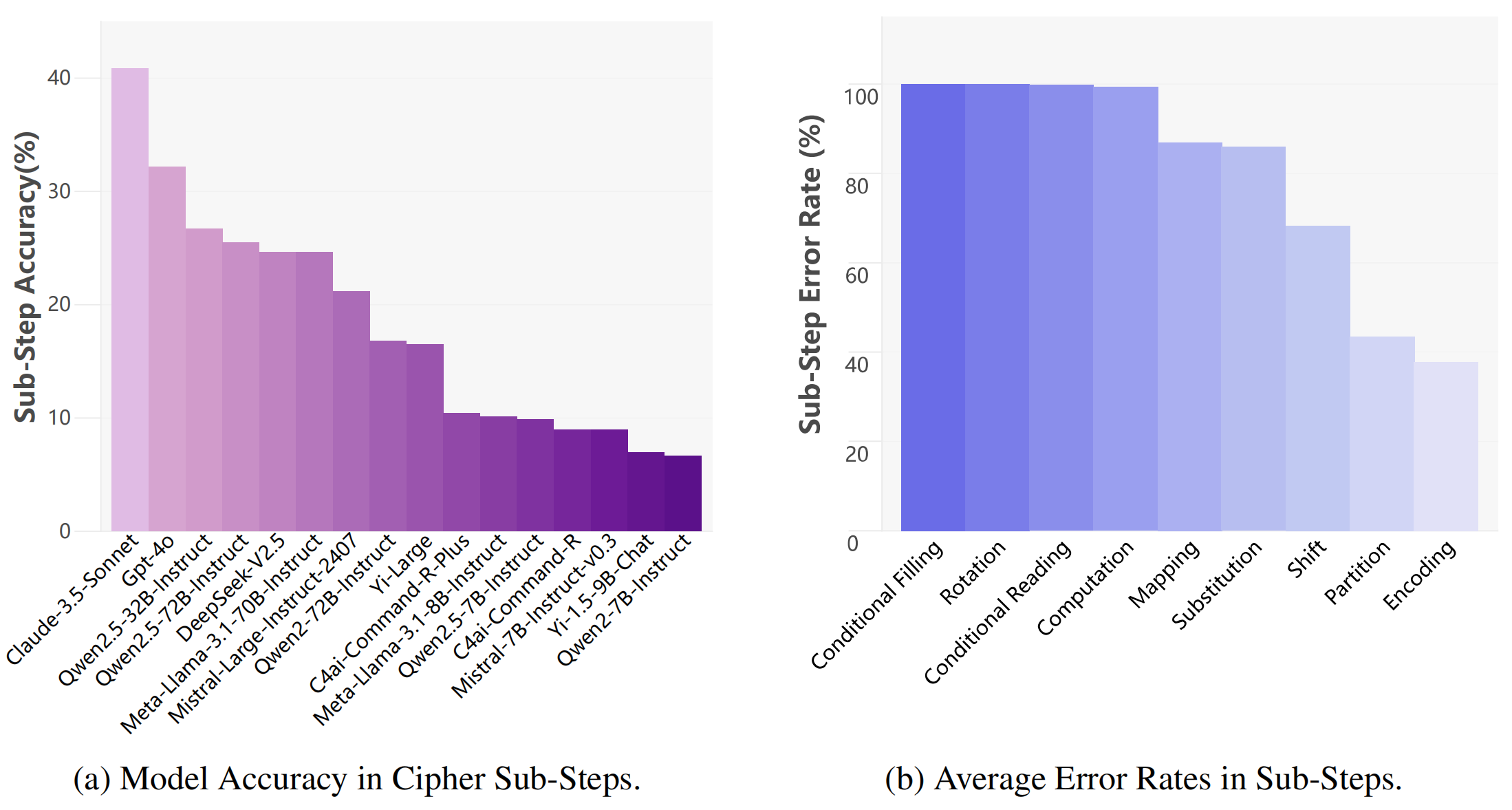
In the Cipher Reasoning task, an analysis of nine sub-steps reveals that while error rates for Encoding and Partition are low, higher error rates in Shift, Mapping, Substitution, and Calculation, along with nearly 100% errors in Rotation, Conditional Filling, and Conditional Reading, indicate significant bottlenecks in the model's reasoning process, particularly in spatial operations.
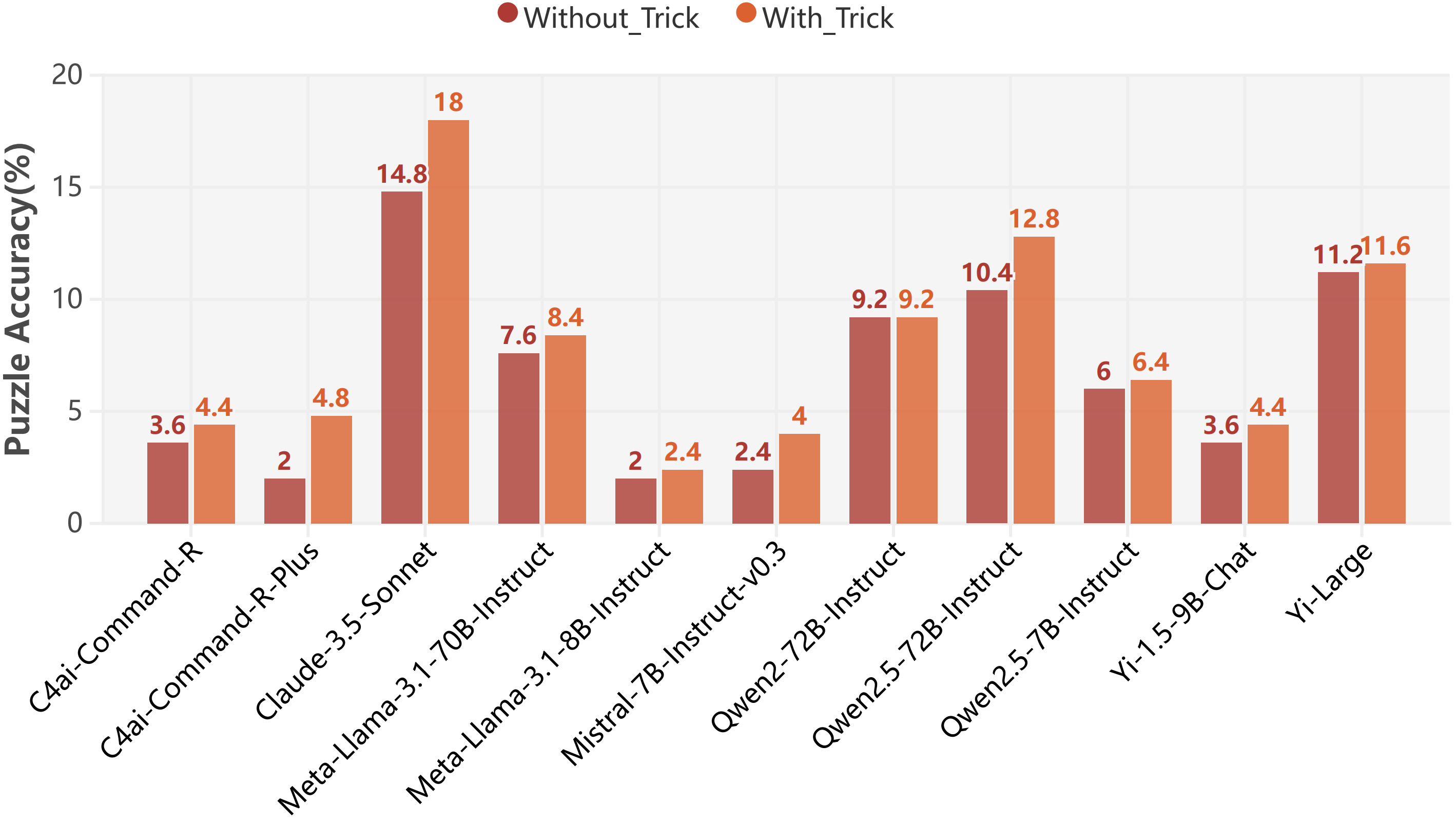
In this experiment, we introduce a "trick" field as additional input to explore its impact on puzzle task performance, noting that while recognizing and executing key initial steps can potentially simplify complex tasks, the results indicate that the effect is not as substantial as anticipated.
We add a "needle" field to each question-answer sample to highlight the core parts the model focuses on. Using the Retrieval Head code, we rank the top 50 retrieval heads and visualize their attention scores on the rule text. This helps us understand the model's output and its errors.
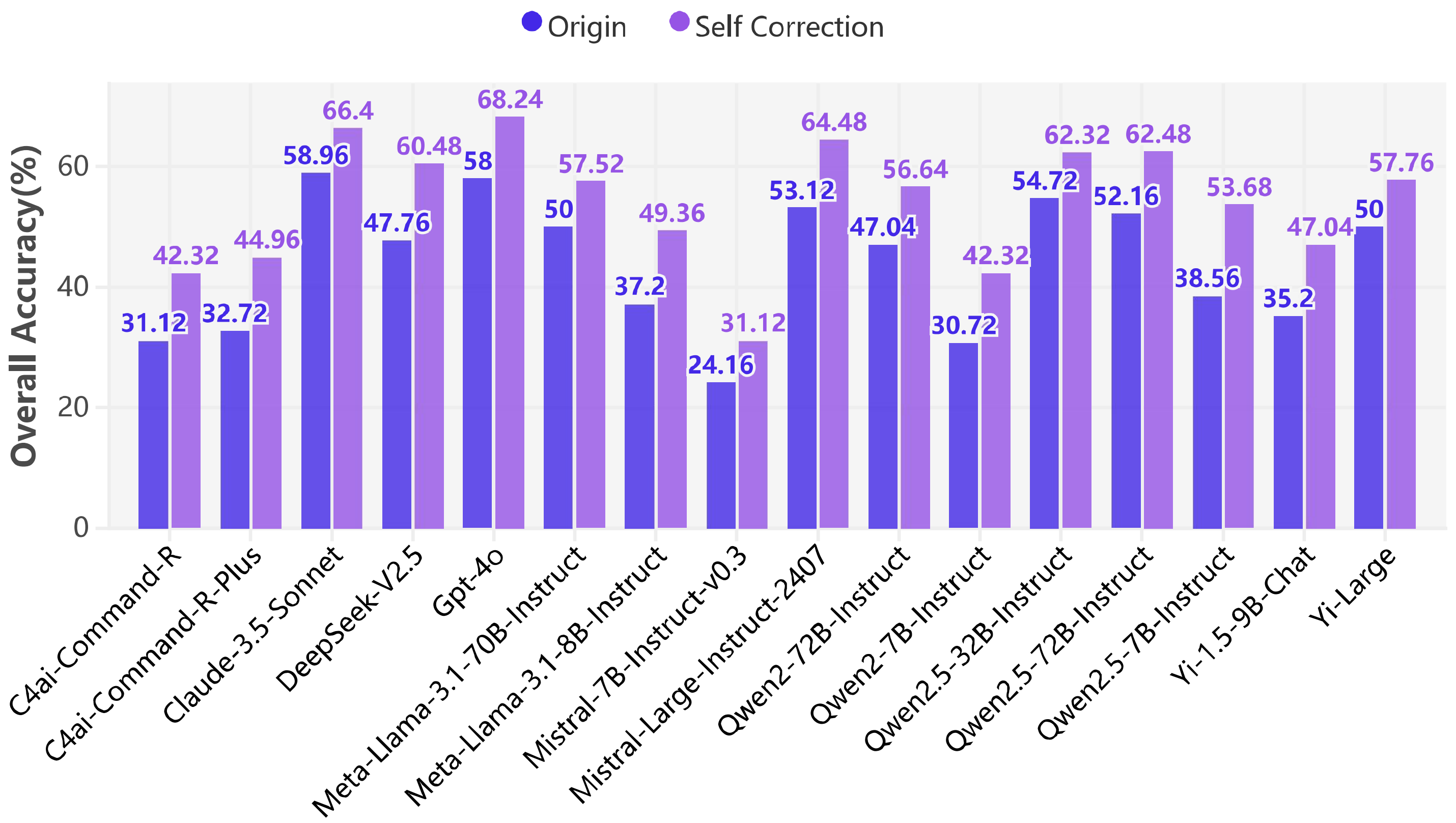
Self-correction in KOR-Bench significantly enhances model performance, with an average improvement of 10.36%, particularly effective in the first two rounds.
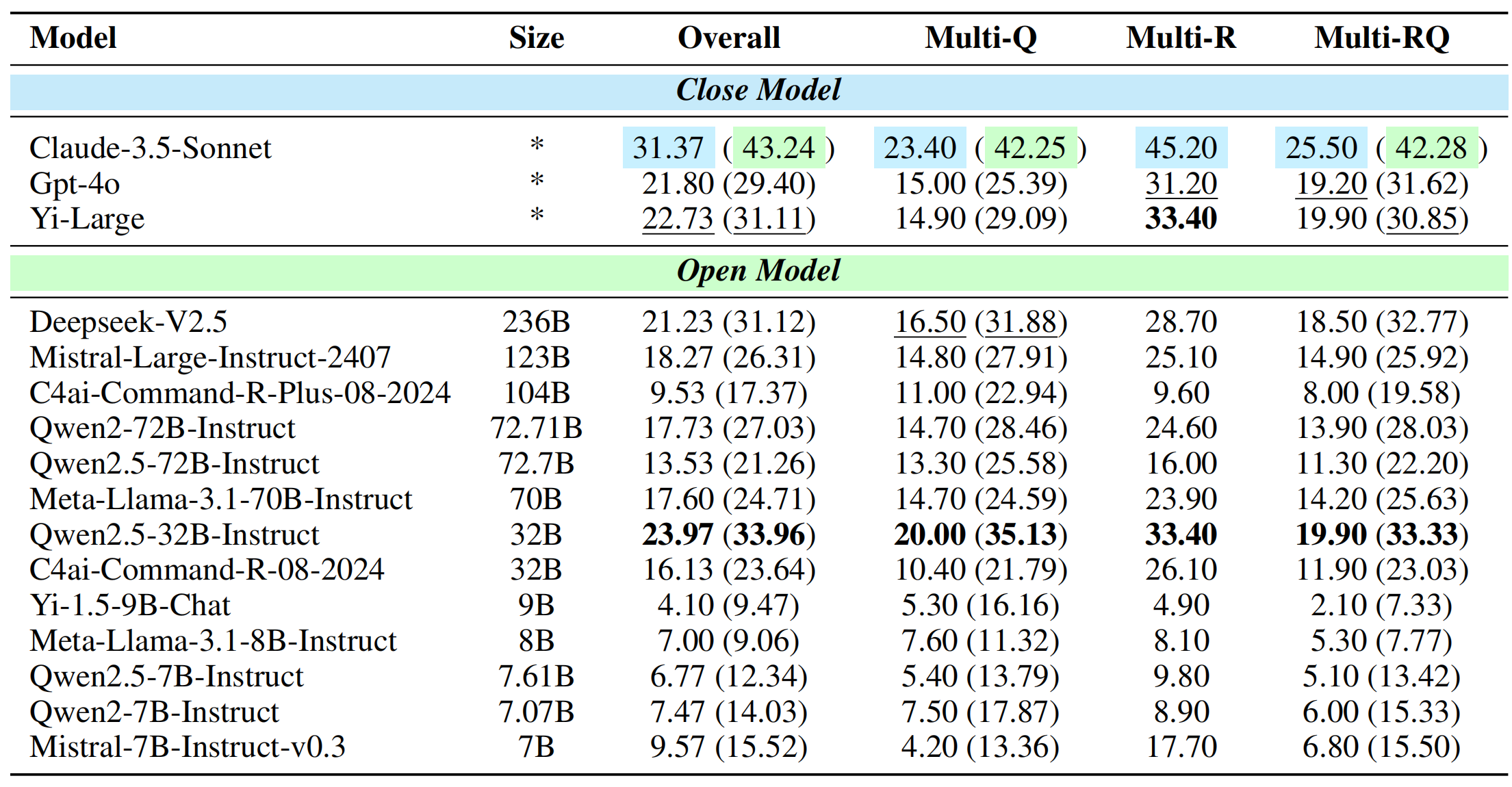
Complex Task Processing experiment focuses on assessing the model's ability to apply rules across three settings: (1) Multi-Q: 1 rule, 1-10 questions; (2) Multi-R: 2-3 rules, 1 question; (3) Multi-RQ: 2-3 rules, 1-3 questions.
@misc{ma2024korbenchbenchmarkinglanguagemodels,
title={KOR-Bench: Benchmarking Language Models on Knowledge-Orthogonal Reasoning Tasks},
author={Kaijing Ma and Xinrun Du and Yunran Wang and Haoran Zhang and Zhoufutu Wen and Xingwei Qu and Jian Yang and Jiaheng Liu and Minghao Liu and Xiang Yue and Wenhao Huang and Ge Zhang},
year={2024},
eprint={2410.06526},
archivePrefix={arXiv},
primaryClass={cs.DB},
url={https://arxiv.org/abs/2410.06526},
}